为什么选择 GreptimeDB
GreptimeDB 是一款为云原生环境设计的开源可观测数据库。我们的核心开发者在构建可观测性平台方面拥有丰富的经验,GreptimeDB 在以下关键领域体现了他们的最佳实践:
统一处理可观测数据
GreptimeDB 通过以下方式统一处理指标、日志和链路追踪:
- 一致的数据模型,将所有可观测数据视为带有上下文的时间戳“宽”事件(Wide Events)
- 原生支持 SQL 和 PromQL 查询
- 内置流处理功能 (Flow),用于实时聚合和分析等
- 跨不同类型的可观测数据进行无缝关联分析(阅读 SQL 示例 了解详细信息)
它用高性能的单一解决方案取代了复杂的传统数据栈。
基于对象存储的成本优势
GreptimeDB 采用云对象存储(如 AWS S3、阿里云 OSS 和 Azure Blob Storage 等)作为存储层,与传统存储方案相比显著降低了成本。通过优化的列式存储和先进的压缩算法,实现了高达 50 倍的成本效率,而按需付费模式的 GreptimeCloud 确保您只需为实际使用的资源付费。
高性能
在性能优化方面,GreptimeDB 运用了多种技术,如 LSM Tree、数据分片和基于 Kafka 的 WAL 设计,以处理大规模可观测数据的写入。
GreptimeDB 使用纯 Rust 编写,具有卓越的性能和可靠性。强大而快速的查询引擎由向量化执行和分布式并行处理(感谢 Apache DataFusion)驱动,并结合了丰富的索引选项,例如倒排索引、调数索引和全文索引等。GreptimeDB将智能索引和大规模并行处理 (MPP) 结合在一起,以提升查询过程中数据剪枝和过滤的效率。
GreptimeDB 在ClickHouse 的 JSONBench 测试中 Cold Run 斩获第一!,更多报告请参阅性能测试报告。
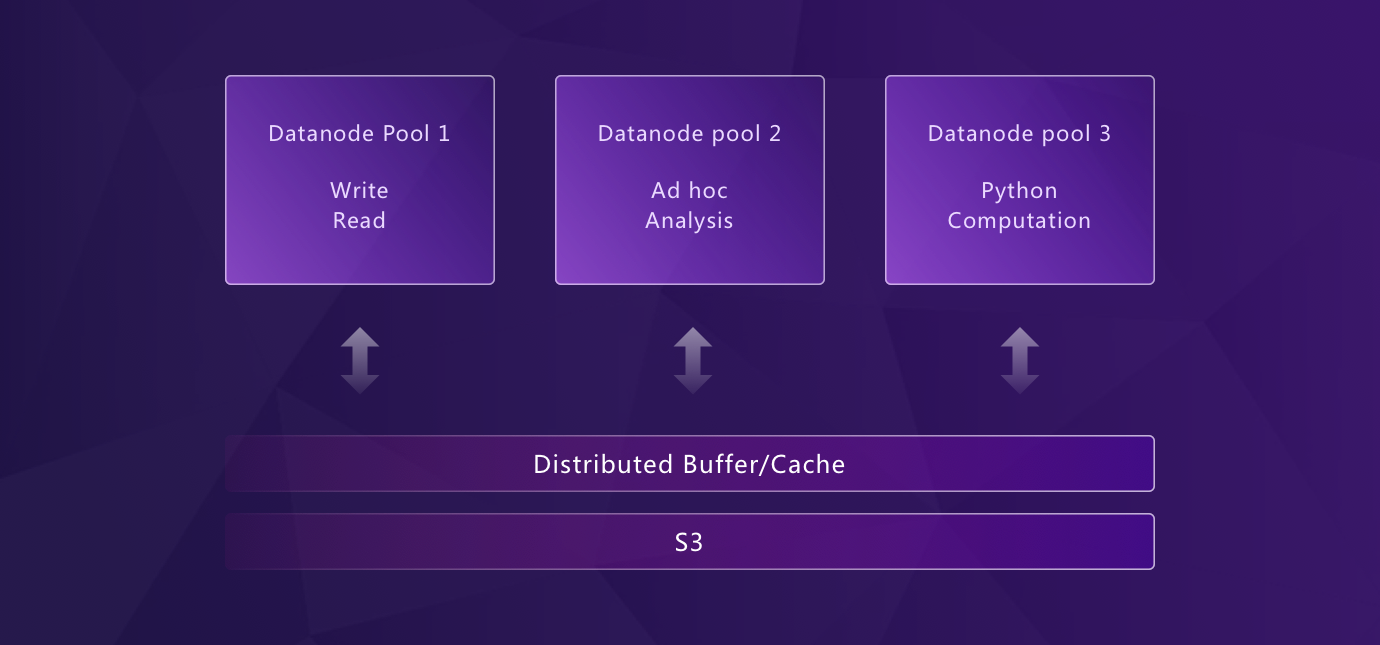
基于 Kubernetes 的弹性扩展
GreptimeDB 从底层就是为 Kubernetes 设计的,基于先进的存储计算分离的架构,实现真正的弹性扩展:
- 存储和计算资源可独立扩展
- 通过 Kubernetes 实现无限水平扩展
- 不同工作负载(数据写入、查询、压缩、索引)之间的资源隔离
- 自动故障转移和高可用性
 。
。
灵活架构:从边缘到云端
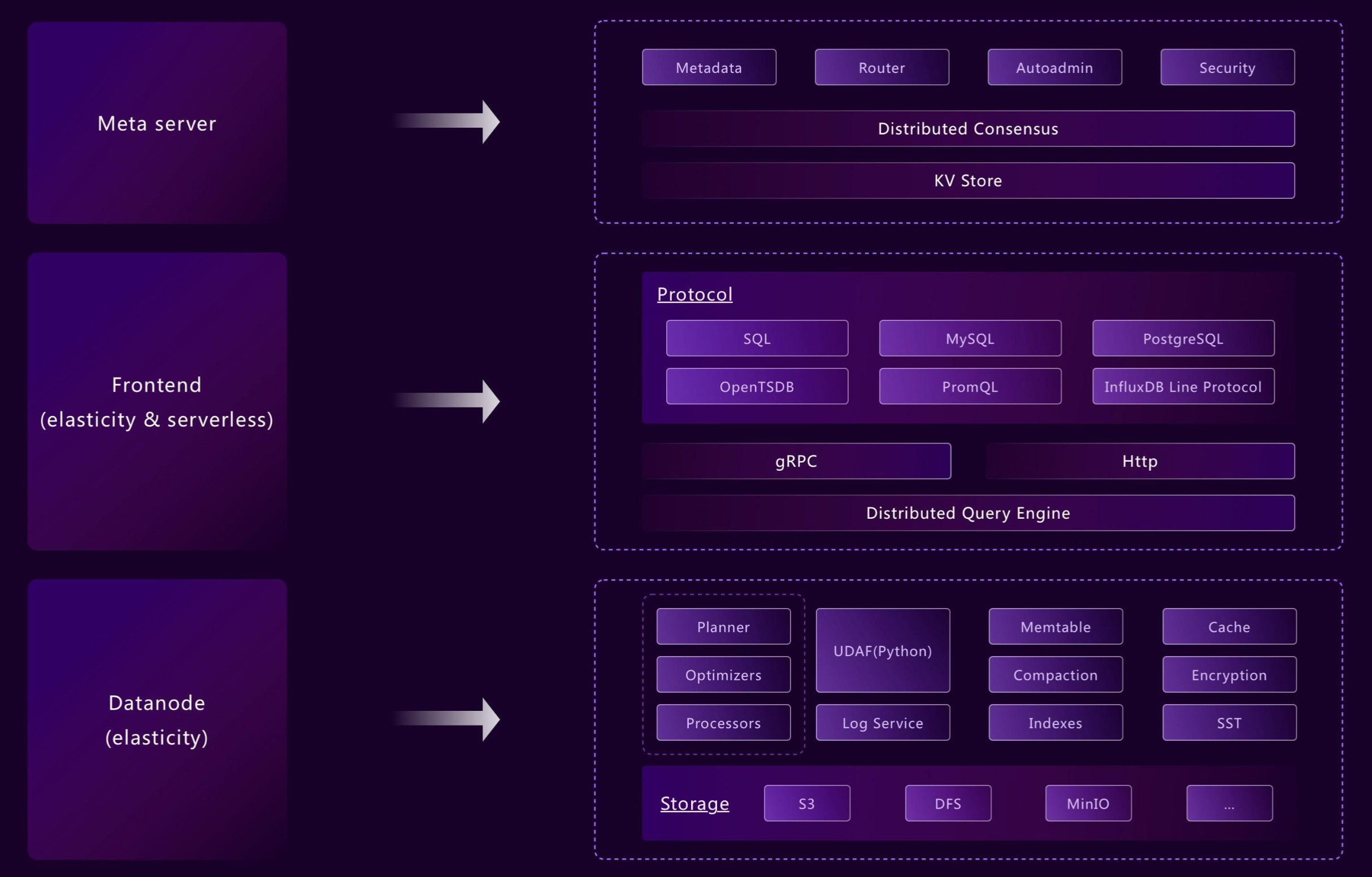
GreptimeDB的模块化架构允许不同的组件根据需要独立运行或协同运行。其灵活的设计支持各种部署场景,从边缘设备到云环境,同时仍然使用一致的API进行操作。 例如:
- Frontend、Datanode 和 Metasrv 可以合并到一个独立的二进制文件中
- 可以为每个表启用或禁用 WAL 或索引等组件
这种灵活性确保了 GreptimeDB 能够满足从边缘到云的解决方案的部署要求,了解边云一体化解决方案。
从嵌入式、单机部署到云原生集群,GreptimeDB 可以轻松适应各种环境。
易于迁移和使用
易于部署和维护
GreptimeDB 通过以下工具简化了部署和维护:
为了获得更简便的体验,请查看完全托管的 GreptimeCloud。
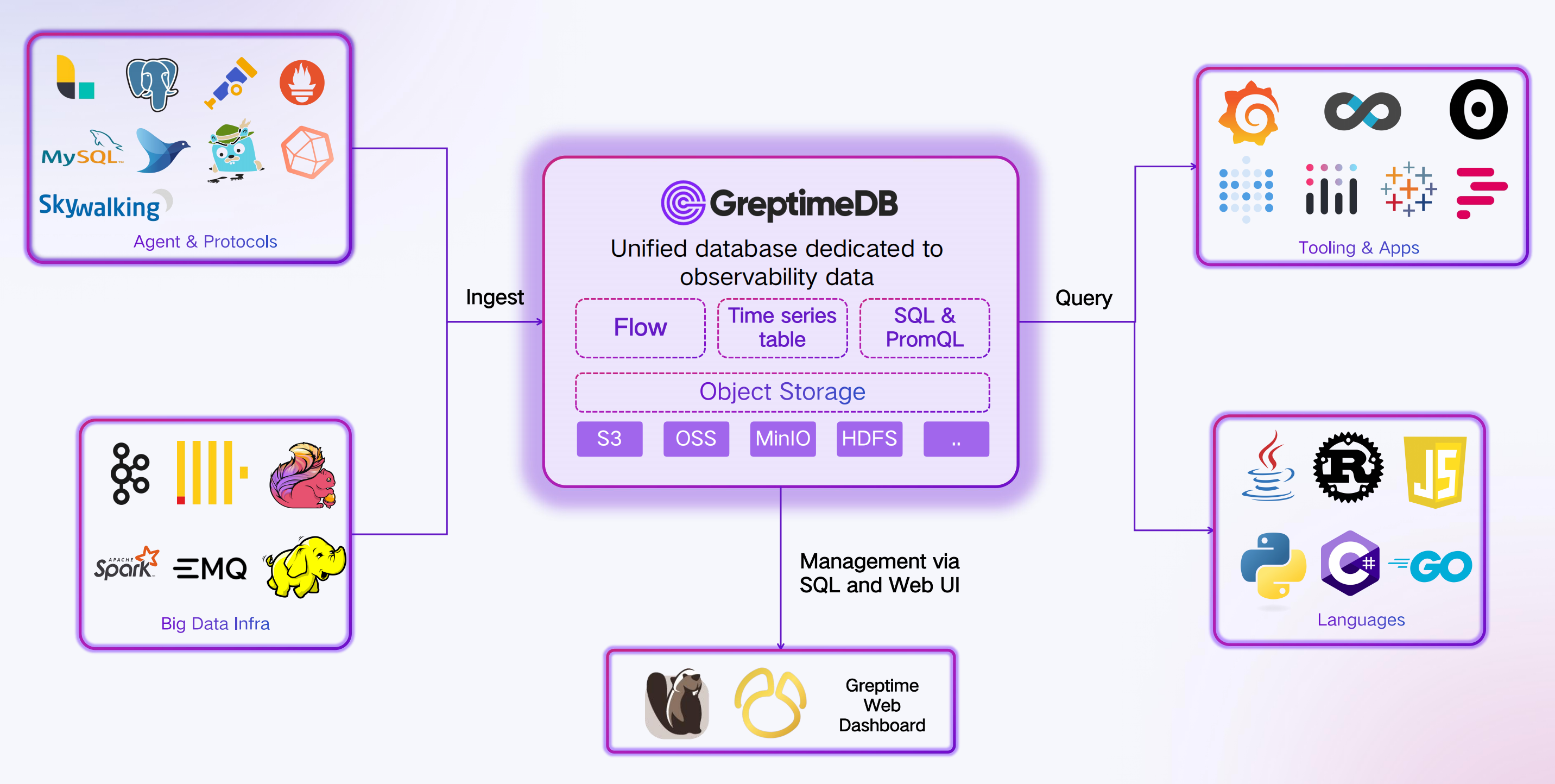
易于集成
GreptimeDB 支持多种数据摄入协议,从而实现与现有可观测性技术栈的无缝集成:
- 数据库协议:MySQL、PostgreSQL
- 时序数据协议:InfluxDB、OpenTSDB、Prometheus RemoteStorage
- 可观测数据协议:OpenTelemetry、Loki、ElasticSearch
- 高性能 gRPC 协议及客户端 SDK(Java、Go、Erlang 等)
在数据查询方面,GreptimeDB 提供:
- SQL:用于实时查询、复杂分析和数据库管理
- PromQL:原生支持实时指标查询和 Grafana 集成
- Python:(计划中)支持数据科学场景的数据库内 UDF 和 DataFrame 操作
GreptimeDB 与您的现有可观测性技术栈无缝集成,同时保持高性能和灵活性。
简单的数据模型与自动创建表
GreptimeDB 引入了一种新的数据模型,该模型结合了时序和关系模型:
- 数据以表格(Table)形式表示,包含行(Row)和列(Column)
- 指标、日志和链路追踪信息映射到列,时间索引(Time Index)用于时间戳列
- Schema 是动态创建的,并且在数据写入时会自动添加新列
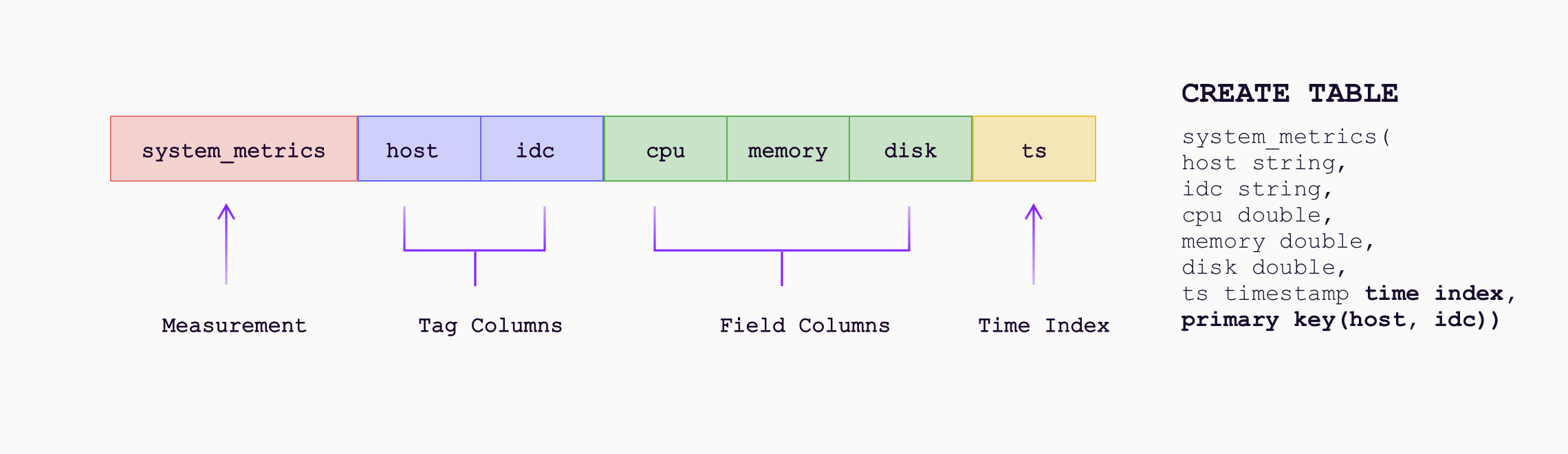
然而,我们对 schema 的定义不是强制性的,而是更倾向于 MongoDB 等数据库的无 schema 方法。 表将在数据写入时动态自动创建,并自动添加新出现的列(Tag 和 Field)。更详细的说明,请阅读数据模型。
要了解更多关于我们的方法和架构,请查看博客文章: